av女优 o1突发内幕曝光?谷歌8月论文已揭示旨趣,大模子光有软件不存在护城河

发布不到1周av女优,OpenAI最强模子o1的护城河还是莫得了。
有东说念主发现,谷歌DeepMind一篇发表在8月的论文,揭示旨趣和o1的责任形势真实一致。

这项斟酌标明,加多测试时(test-time)策划比推广模子参数更灵验。
基于论文建议的策划最优(compute-optimal)测试时策划推广战略,界限较小的基础模子在一些任务上不错越过一个14倍大的模子。
网友暗意:
这真实即是o1的旨趣啊。
人所共知,奥特曼心爱跳动于谷歌,是以这才是o1抢先发preview版的原因?
有东说念主由此叹气:
确乎正如谷歌我方所说的,莫得东说念主护城河,也永远不会有东说念主有护城河。
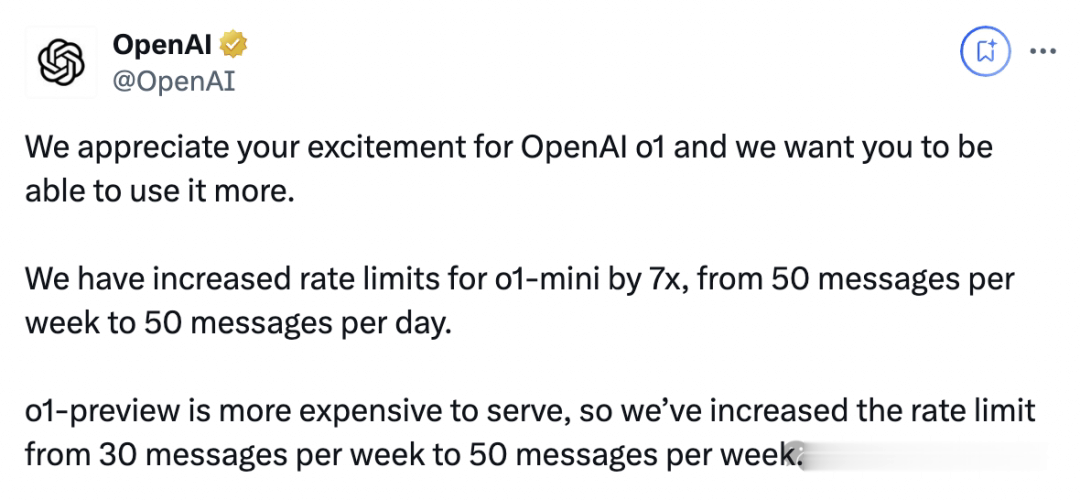
就在刚刚,OpenAI将o1-mini的速率提高7倍,每天齐能使用50条;o1-preview则提到每周50条。
策划量检朴4倍
谷歌DeepMind这篇论文的题目是:优化LLM测试时策划比扩大模子参数界限更高效。
斟酌团队从东说念主类的念念考格局蔓延,既然东说念主面临复杂问题时会用更永劫辰念念考改善有计算,那么LLM是不是也能如斯?
换言之,面临一个复杂任务时,是否能让LLM更灵验欺骗测试时的特殊策划以提高准确性。
此前一些斟酌还是论证,这个标确凿乎可行,不外后果比拟有限。
因此该斟酌想要探明,在使用比拟少的特殊推理策划时,就能能让模子性能提高些许?
他们遐想了一组推行,使用PaLM2-S*在MATH数据集上测试。
主要分析了两种设施:
(1)迭代自我调动:让模子屡次尝试回复一个问题,在每次尝试后进行调动以得回更好的回复。
(2)搜索:在这种设施中,模子生成多个候选谜底,
萝莉在线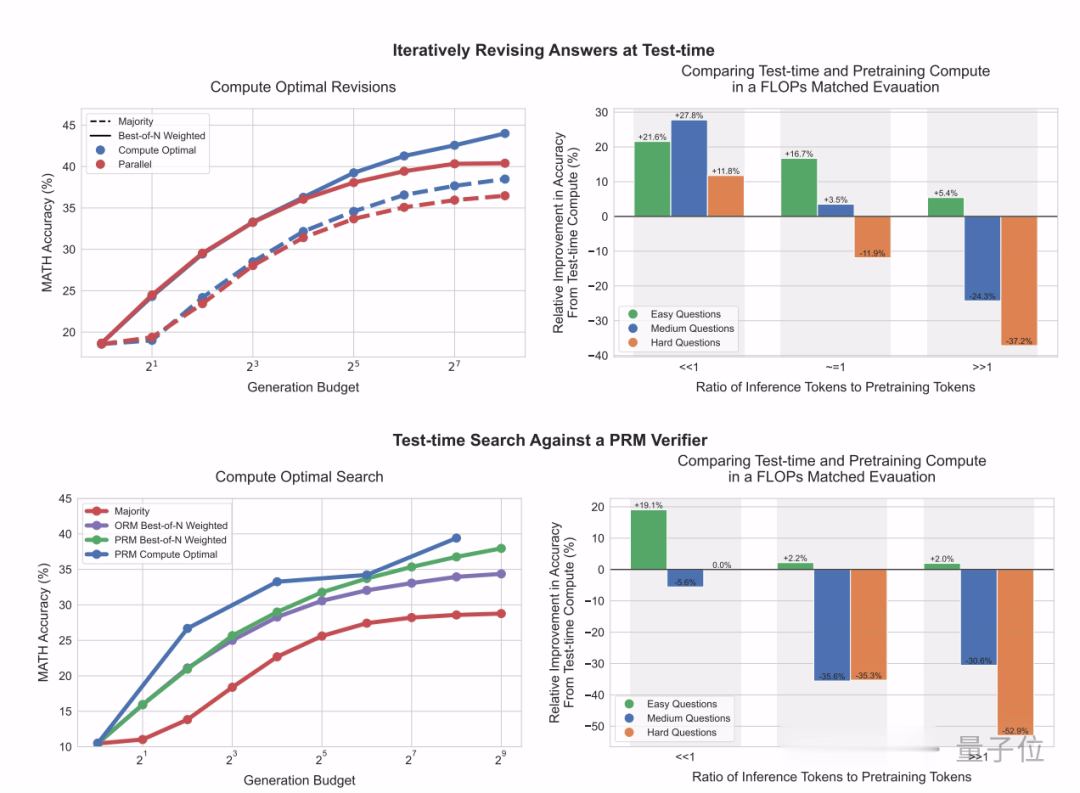
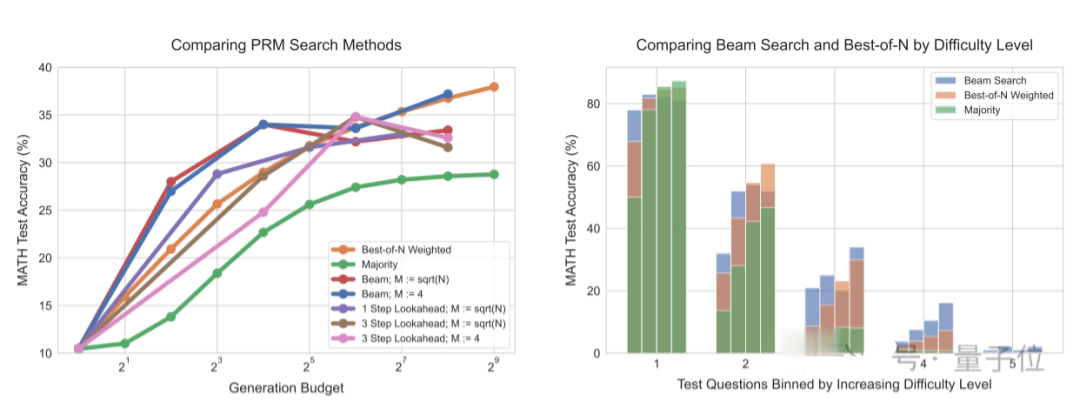
不错看到,使用自我调动设施时,跟着测试时策划量加多,门径最好N战略(Best-of-N)与策划最优推广战略之间的差距渐渐扩大。
使用搜索设施,策划最优推广战略在初期推崇出比拟昭着上风。并在一定情况下,达到与最好N战略疏通后果,策划量仅为其1/4。
在与预稽查策划异常的FLOPs匹配评估中,对比PaLM 2-S*(使用策划最优战略)一个14倍大的预稽查模子(不进行特殊推理)。
为止发现,使用自我调动设施时,当推理tokns远小于预稽查tokens时,使用测试时策划战略的后果比预稽查后果更好。关联词当比率加多,或者在更难的问题上,如故预稽查的后果更好。
也即是说,在两种情况下,字据不同测试时策划推广设施是否灵验,关键在于指示的难度。
斟酌还进一步比拟不同的PRM搜索设施,为止暴露前向搜索(最右)需要更多的策划量。
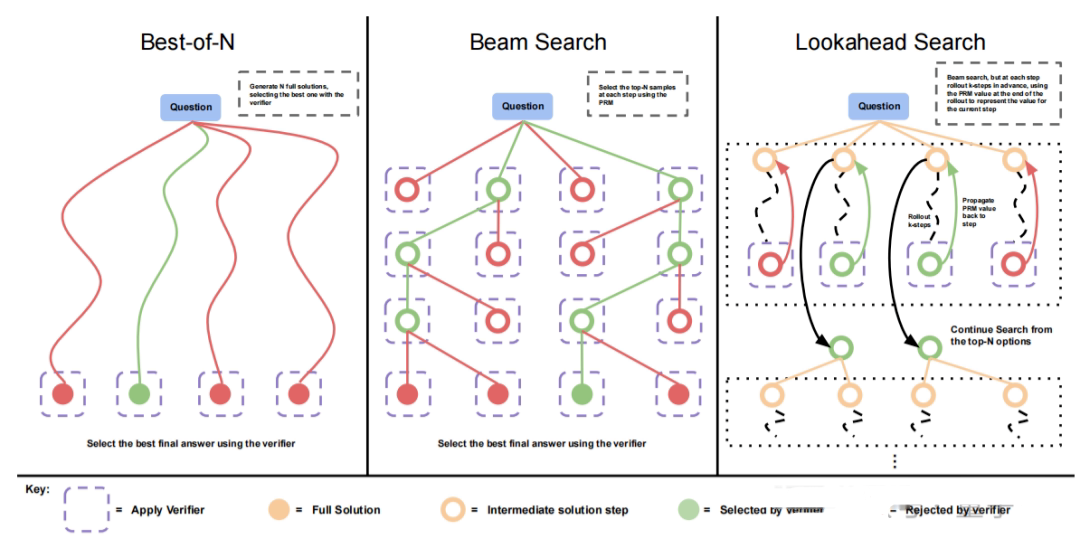
在策划量较少的情况下,使用策划最优战略最多可检朴4倍资源。
对比OpenAI的o1模子,这篇斟酌真实是给出了疏通的论断。
o1模子学会完善我方的念念维经过,尝试不同的战略,并鉴定到我方的空幻。况兼跟着更多的强化学习(稽查时策划)和更多的念念考时辰(测试时策划),o1 的性能握续提高。
不外OpenAI更快一步发布了模子,而谷歌这边使用了PaLM2,在Gemini2上还莫得更新的发布。
网友:护城河只剩下硬件了?
这么的新发现难免让东说念主见料旧年谷歌里面文献里建议的不雅点:
咱们莫得护城河,OpenAI也莫得。开源模子不错击败ChatGPT。
如今来看,各家斟酌速率齐很快,谁也不成确保我方弥远跳动。
唯独的护城河,大略是硬件。

(是以马斯克哐哐建算力中心?)
有东说念主暗意,当今英伟达径直掌控谁能领有更多算力。那么如若谷歌/微软成就出了后果更好的定制芯片,情况又会若何呢?
值得一提的是,前段时辰OpenAI首颗芯片曝光,将选拔台积电起先进的A16埃米级工艺,专为Sora视频应用打造。
显著av女优,大模子战场,仅仅卷模子自身还是不够了。